I downloaded the latest BOSS data and randoms from Will Percival as Martin White suggested in my email exchange with him yesterday.
There are in the following location on the wiki:
https://trac.sdss3.org/wiki/BOSS/clustering/cats
I put them here on riemann:
/clusterfs/riemann/raid001/jessica/boss/
galaxy-wjp-main008-LOWZ-020211-cut.txt
random-wjp-main008-LOWZ-020211-cut-small.txt
galaxy-wjp-merge-CMASS-020211-cut.txt
random-wjp-merge-CMASS-020211-cut-small.txt
The format of these files is:
ra / degrees
dec / degrees
redshift
galaxy weight
sector completeness
close pair flag
THING_ID
MASK POLY ID
ID for galaxy in spAll file (not in std format)
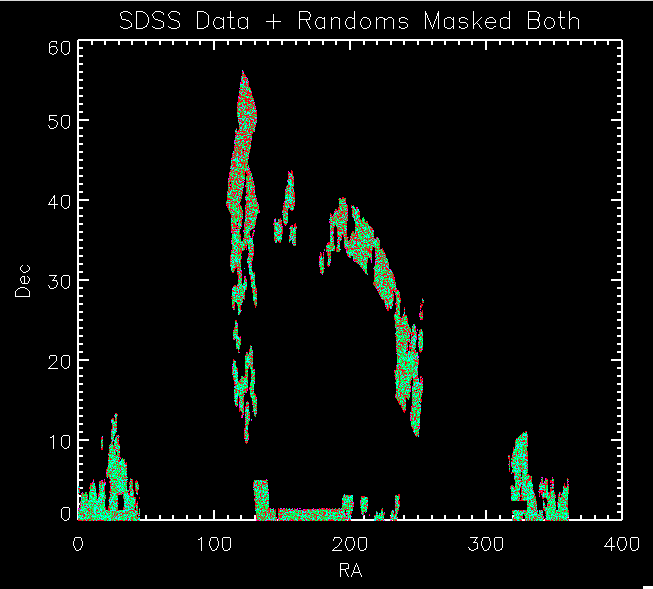
I read them in and below are plots. As you can see, the distribution of the randoms matches the data. So there is something wrong with what I am doing. At this point though, I'm not going to waste more time trying to fix my masks/randoms. I'm going to use these catalogs and re-run the correlation functions to see if this fixes things.
I'm also going to ask Shirley or Eric to run a correlation function on the same data to check that we get the same answer.








The code to make the above plots is in the following log file:
../logs/110302log/pro
thisfile = '/clusterfs/riemann/raid001/jessica/boss/galaxy-wjp-main008-LOWZ-020211-cut.txt'
readcol,thisfile,slra,sldec,slz,x,x,x,x,x,x,format='(F,F,F,F,F,F,F,F,F)'
thisfile = '/clusterfs/riemann/raid001/jessica/boss/galaxy-wjp-merge-CMASS-020211-cut.txt'
readcol,thisfile,sra,sdec,sz,x,x,x,x,x,x,format='(F,F,F,F,F,F,F,F,F)'
sra = [sra,slra]
sdec = [sdec,sldec]
sz = [sz,slz]
thisfile = '/clusterfs/riemann/raid001/jessica/boss/random-wjp-main008-LOWZ-020211-cut-small.txt'
readcol,thisfile,rslra,rsldec,rslz,x,x,x,x,x,x,format='(F,F,F,F,F,F,F,F,F)'
thisfile = '/clusterfs/riemann/raid001/jessica/boss/random-wjp-merge-CMASS-020211-cut-small.txt'
readcol,thisfile,rsra,rsdec,rsz,x,x,x,x,x,x,format='(F,F,F,F,F,F,F,F,F)'
rsra = [rsra,rslra]
rsdec = [rsdec,rsldec]
rsz = [rsz,rslz]
xtit = 'Ra'
ytit = 'Dec'
mtit = 'Ra vs Dec'
window,xsize=700,ysize=600
plot, sra, sdec, ps = 3, xrange = [110,130], yrange=[40,55],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
oplot, rsra, rsdec, ps=3, color = fsc_color('green')
;Make histogram of the dec distributions
data = sdec
datamin = min(sdec)
datamax = max(sdec)
binsize = (datamax - datamin)/100
xtit = 'Dec Distribution'
ytit = '% in bin'
mtit = 'Histogram of Spectroscopic Dec'
window,xsize=700,ysize=600
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
plot, bins, hist*1.0/n_elements(data), PSYM = 10, xrange = [datamin,datamax], yrange=[0,1.0*max(hist)/n_elements(data)],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
data = rsdec
datamin = min(rsdec)
datamax = max(rsdec)
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
oplot, bins, 1.0*hist/n_elements(data), PSYM = 10, color = fsc_color('green')
;Make histogram of the dec distributions
data = sdec
datamin = min(sdec)
datamax = max(sdec)
binsize = (datamax - datamin)/1000
xtit = 'Dec Distribution'
ytit = '# in bin'
mtit = 'Histogram of Spectroscopic Dec'
window,xsize=700,ysize=600
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
plot, bins, hist*1.0, PSYM = 10, xrange = [datamin,datamax], yrange=[0,1.0*max(hist)],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
data = rsdec
datamin = min(rsdec)
datamax = max(rsdec)
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
oplot, bins, 1.0*hist, PSYM = 10, color = fsc_color('green')
;Make histogram of the dec distributions
data = sra
datamin = min(sra)
datamax = max(sra)
binsize = (datamax - datamin)/100
xtit = 'Ra Distribution'
ytit = '% in bin'
mtit = 'Histogram of Spectroscopic Ra'
window,xsize=700,ysize=600
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
plot, bins, hist*1.0/n_elements(data), PSYM = 10, xrange = [datamin,datamax], yrange=[0,1.0*max(hist)/n_elements(data)],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
data = rsra
datamin = min(rsra)
datamax = max(rsra)
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
oplot, bins, 1.0*hist/n_elements(data), PSYM = 10, color = fsc_color('green')
;Make histogram of the dec distributions
data = sra
datamin = min(sra)
datamax = max(sra)
binsize = (datamax - datamin)/1000
xtit = 'RA Distribution'
ytit = '# in bin'
mtit = 'Histogram of Spectroscopic RA'
window,xsize=700,ysize=600
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
plot, bins, hist*1.0, PSYM = 10, xrange = [datamin,datamax], yrange=[0,1.0*max(hist)],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
data = rsra
datamin = min(rsra)
datamax = max(rsra)
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
oplot, bins, 1.0*hist, PSYM = 10, color = fsc_color('green')
;Make histogram of the z distributions
data = sz
datamin = min(sz)
datamax = max(sz)
binsize = (datamax - datamin)/50
xtit = 'Redshift Distribution'
ytit = '% in bin'
mtit = 'Histogram of Spectroscopic z'
window,xsize=700,ysize=600
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
plot, bins, hist*1.0/n_elements(data), PSYM = 10, xrange = [datamin,datamax], yrange=[0,1.0*max(hist)/n_elements(data)],XTITLE = xtit, YTITLE =ytit, TITLE = mtit, charsize = 1.5, charthick = 1
data = rsz
datamin = min(rsz)
datamax = max(rsz)
hist = HISTOGRAM(data, binsize = binsize, min = datamin, max = datamax)
bins = FINDGEN(N_ELEMENTS(hist))*binsize + datamin
oplot, bins, 1.0*hist/n_elements(data), PSYM = 10, color = fsc_color('green')
;Plot Data that is inside the mask
window,xsize=700,ysize=600
xobject = sra
yobject = sdec
xtit = 'RA'
ytit = 'Dec'
mtit = 'SDSS Spectroscopic Data + Masks'
plot, xobject, yobject, psym=3, symsize=2, XTITLE = xtit, YTITLE = ytit, TITLE = mtit, charsize = 2, charthick = 1, thick = 2, xthick=2, ythick=2
oplot, xobject, yobject, ps=3, color=fsc_color('white')
oplot, rsra, rsdec, ps=3, color=fsc_color('green')