I did a little bit of thinking about the number of grids for the correlation function. There is the strange balance that you want the number of grids to be less than the number of particles, otherwise you might as well just correlate all possible pairs. You also want the spacing to be much bigger than the max correlation length, otherwise even by going out one grid length, you will unnecessarily correlate too many objects. I feel like this is a computer science problem, and perhaps Adam Pauls or Erin Sheldon would know the answer?
I played with this a bit (tried upping the grid points to 1000, and this took forever to run). For the 2D correlation function, I am correlating out to a distance of 0.34 (with a box size of 1). Maybe I don't need to correlate out to such a big angle? We could probably have as few as 10 grid points in each dimension if we are going out to this large of an angle. For the 3D correlation function, I am correlating out to a distance of 20 Mpc/h (with a box size of 2400 Mpc/h) so we need at least ~120 grid points in each dimension.
For the 3D correlation function, some of the larger redshift bins have very few objects in them, and if we have ~1003 or 106 grid points then we are wasting time griding if we have less than 103 points in each set.
Here are the results from the reconstruction I ran yesterday. It looks like I don't have enough points because the correlation functions are very noisy.

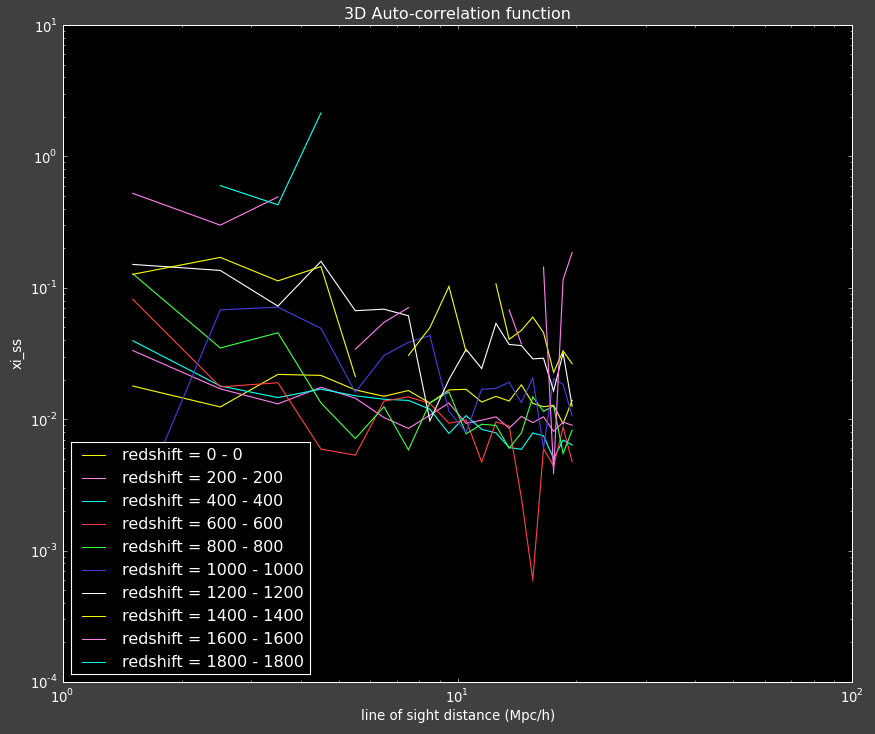
The reconstructions don't look good and are highly variable:


I'm running on a bigger data set now.

No comments:
Post a Comment