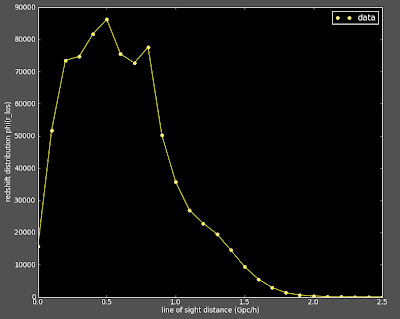
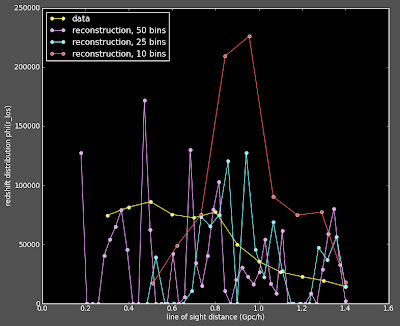
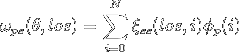I have been working on systematically changing my 2D correlation function (which matches Alexia's 2d correlation function) to a 3D correlation function (which was looking very different from Alexia's 3D). I haven't made all the changes, but of those I have made thus far, I still get matching functions:

I haven't put in the coordinate changes yet (which is the major change, and probably the root of my problem). Let this experience be a reminder to me that I shouldn't make multiple changes at once to my code.
If you are wondering why this plot of Alexia's Xi looks different than the one in the Miserable Failure post, this is because that 3D correlation function was using an older version of Alexia's code which only looks at the correlation function in a cone with a 12 degree open angle. This version of her code calculates the correlation function on the entire box.
If you are wondering why this plot of Alexia's Xi looks different than the one in the Miserable Failure post, this is because that 3D correlation function was using an older version of Alexia's code which only looks at the correlation function in a cone with a 12 degree open angle. This version of her code calculates the correlation function on the entire box.
Time for the 'State of the Department' address. Predicted summary: We are broke!